OpenAI 发布 MRC:大模型竞争,拼到数据中心网络了
你以为大模型公司的竞争,还是谁的模型更会写代码、谁的上下文更长、谁的推理更聪明?
OpenAI 这篇工程文章提醒了一件更底层的事:模型能力继续往上堆,瓶颈已经不只在算法,也不只在显卡数量,而是在数据中心网络。
说得更直白一点:
你买到十万张显卡,不等于你拥有十万张显卡的训练能力。
如果网络一抖、链路一堵、交换机一重启,成千上万张图形处理器(GPU)就可能互相等。同步训练最怕的不是平均速度慢,而是某一小段通信突然慢下来。最慢的那一下,会拖住整个训练步。
所以 OpenAI 这次发布的多路径可靠连接(MRC),看起来是一篇“网络工程博客”,实际是在讲一个更大的判断:
大模型竞争,已经打到超级计算网络协议层了。
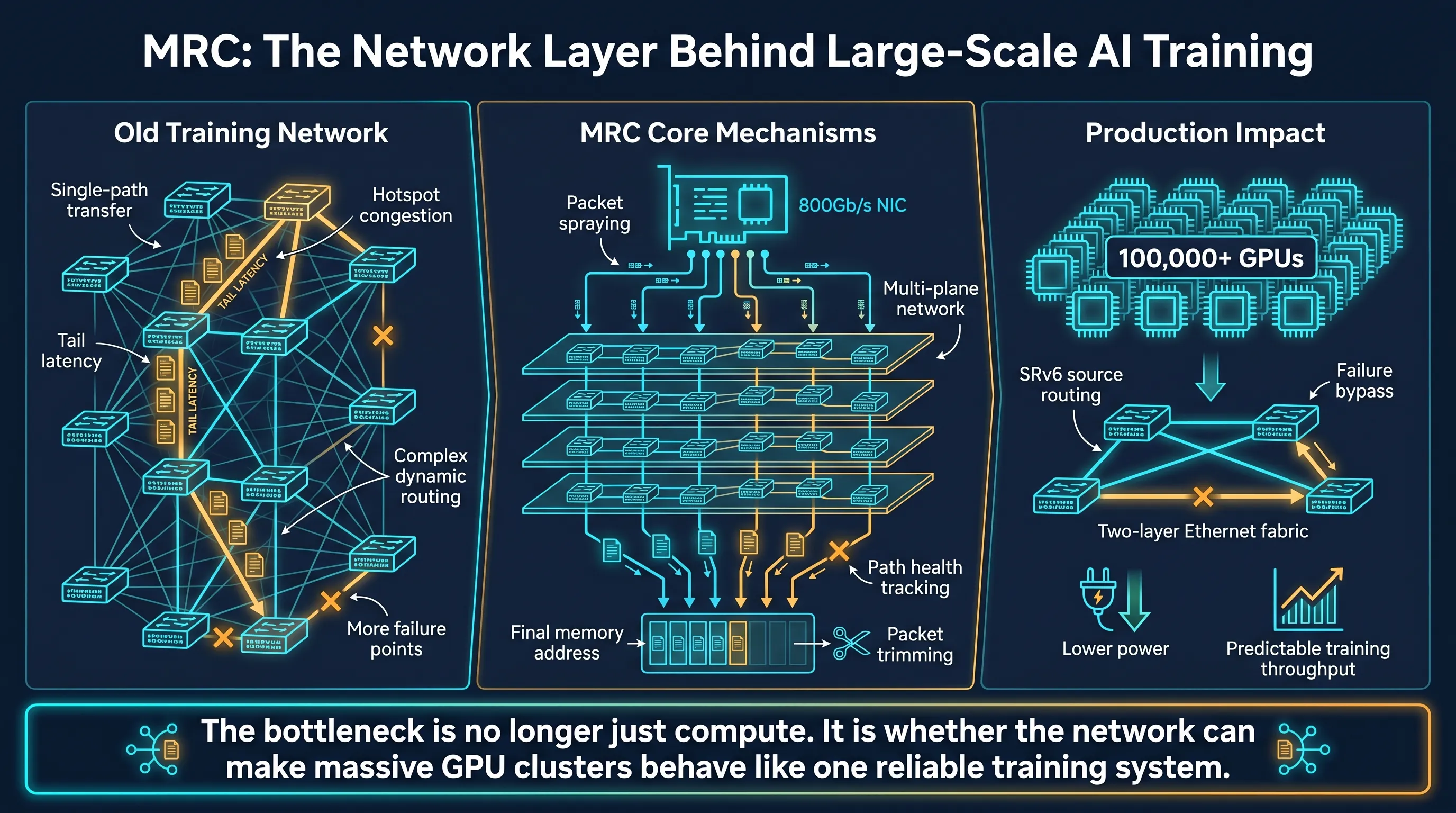
旧问题:显卡越多,网络越像薄弱环节
前沿模型训练不是一堆显卡各干各的。
训练过程中,图形处理器(GPU)之间要持续同步梯度、参数和中间结果。规模越大,通信越频繁。只要其中一部分传输变慢,其他显卡就会等它。
这就是同步训练的残酷之处:你不是按平均链路速度结账,而是按最慢那部分付费。
传统网络方案的问题有三个。
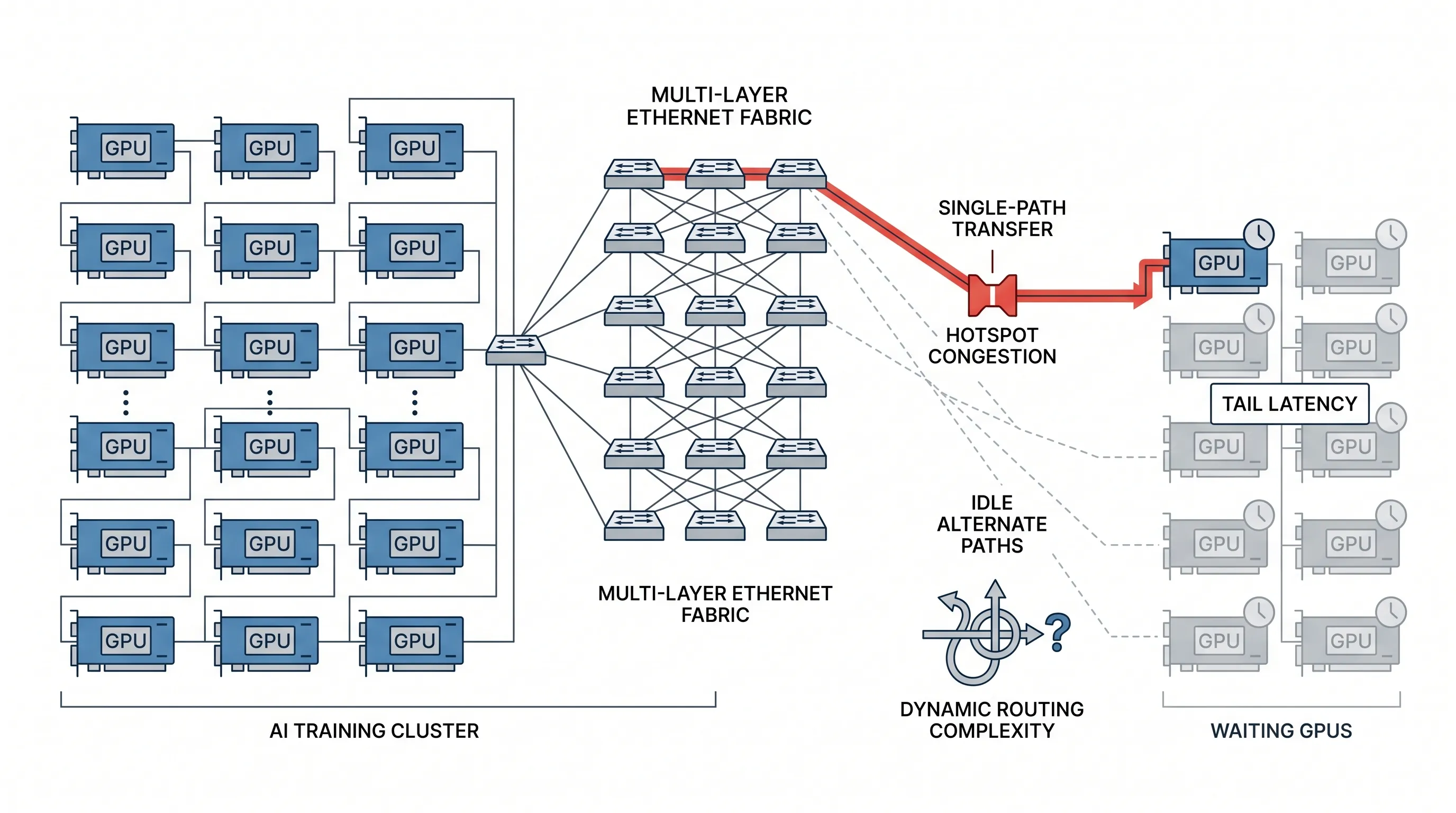
第一,路径太固定。
很多训练网络会让一次传输沿着一条路径走。这样做的好处是包顺序简单,坏处是大规模集群里很容易撞上热点。某几条链路变成高速路收费站,其他路径却没吃满。
第二,网络层级太多。
OpenAI 在文章里举了一个关键例子:传统 800Gb/s 网络想连接超大规模图形处理器(GPU)集群,可能需要三层甚至四层交换机。层级越多,设备越多,功耗越高,故障点也越多。
第三,动态路由太复杂。
传统交换机会跑边界网关协议(BGP)这类动态路由协议,由交换机自己计算路径、绕开故障。这个模式在普通网络里很成熟,但到了大规模训练网络里,控制面会变得很复杂。出了问题以后,排障也更难。
这不是“网速不够快”的问题。
这是“网络不够可预测”的问题。
AI 训练真正需要的不是某一次峰值跑得漂亮,而是在链路抖动、设备故障、流量拥塞都存在的情况下,仍然能稳定推进训练。
新机制:MRC 不是更快的网线,而是更稳的训练织物
OpenAI 这次和超威半导体(AMD)、博通(Broadcom)、英特尔(Intel)、微软(Microsoft)、英伟达(NVIDIA)一起做的多路径可靠连接(MRC),目标不是简单把带宽做大。
它要解决的是:如何让上十万张图形处理器(GPU)像一台更可靠的大机器一样训练。
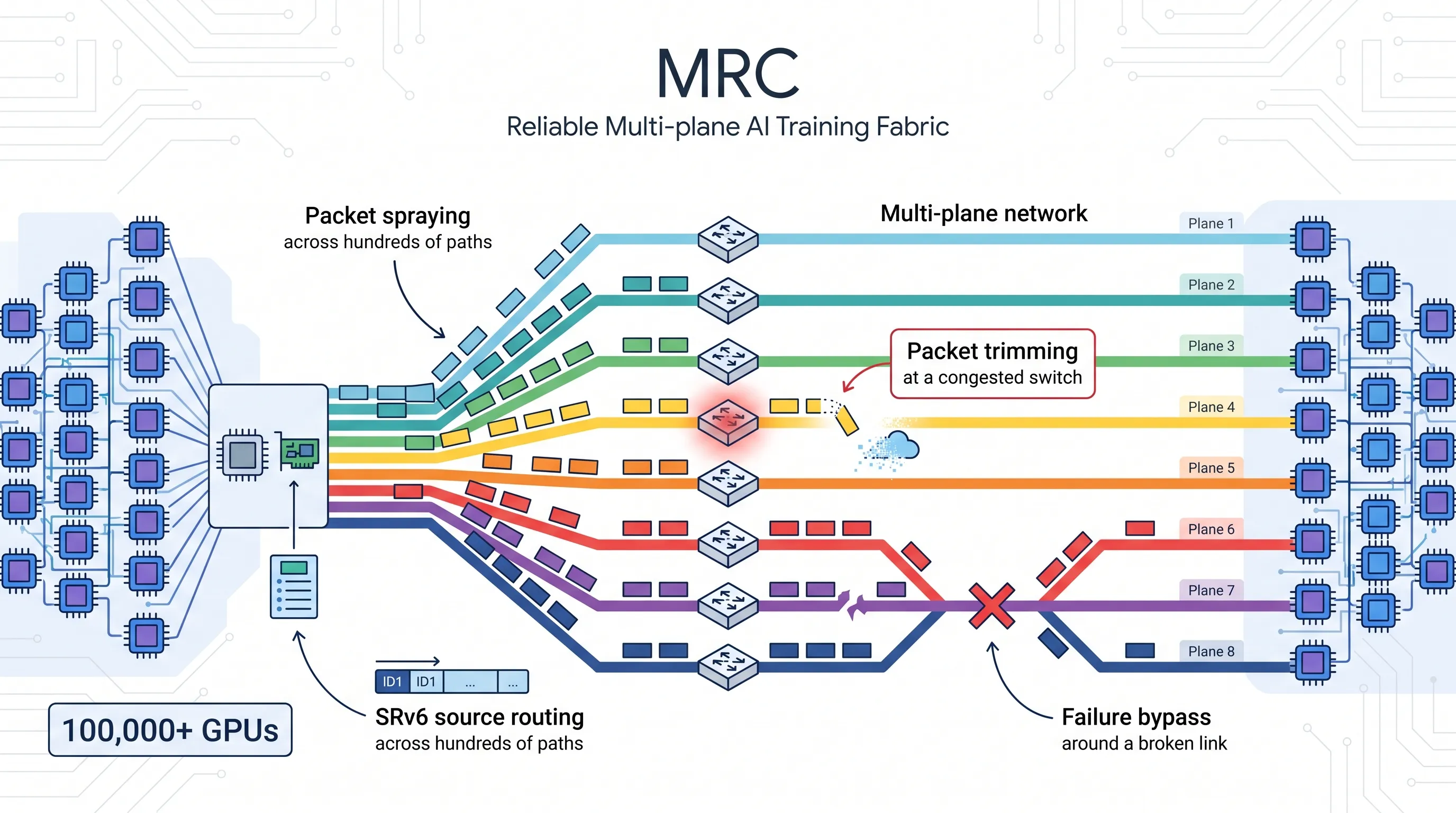
第一层变化,是多平面网络(multi-plane network)。
原来一个 800Gb/s 网络接口,容易被理解成一条很粗的高速路。多路径可靠连接(MRC)的做法,是把它拆成多个更小的链路,比如连到 8 台不同交换机,形成 8 个并行网络平面。
这个设计很关键。
OpenAI 说,借助这种方式,可以用两层以太网交换机构建连接超过 100,000 个图形处理器(GPU)的网络。传统方案可能需要三层或四层。
两层意味着什么?
不是架构图少画一层那么简单,而是更少设备、更低功耗、更少故障点,也有更多可绕行路径。
第二层变化,是包喷洒(packet spraying)。
过去一次传输通常沿一条路径走。多路径可靠连接(MRC)不这么干。它会把一次传输拆成数据包,喷洒到数百条路径上,跨多个网络平面同时传输。
这听起来会带来一个麻烦:包乱序到了怎么办?
多路径可靠连接(MRC)的处理方式是,每个包里带着最终内存地址。接收端不需要等所有包按顺序排好队,而是可以按地址把数据放回正确位置。
这一步非常重要。
它把网络从“排队过独木桥”,变成了“多条路同时送货,到了以后按门牌号放好”。
对同步训练来说,这能减少热点链路,降低尾延迟。也就是说,不再让某一条慢路径拖住整个训练步。
第三层变化,是路径状态管理。
多路径可靠连接(MRC)会维护路径状态。如果某条路径拥塞,就换路径。如果发生丢包,它会保守地假设这条路径可能出问题,暂停使用,并重传可能丢失的数据包。同时,它还会用探测包(probe packets)检查路径是不是恢复了。
这比“等网络自己收敛”更主动。
第四层变化,是包修剪(packet trimming)。
交换机遇到目的端拥塞时,传统做法可能是直接丢包。多路径可靠连接(MRC)支持一种更精细的处理:剪掉载荷(payload),保留头部(header)继续转发给目的端。
这样目的端至少知道“这个包来过,但内容没送到”,可以触发明确重传。好处是减少误判:系统不用把所有丢包都当成路径彻底坏了。
第五层变化,是源路由(source routing)。
这是我认为最值得基础设施团队关注的部分。
传统动态路由让交换机自己算路。多路径可靠连接(MRC)基于第六版分段路由(SRv6),让发送端把路径编码进包的目的地址里。交换机只按静态路由表转发,不再承担复杂的动态路径计算。
换句话说,复杂性从交换机控制面,转移到了端侧协议。
如果某条路径坏了,端侧停止使用它。交换机不需要重新算一大堆路由,也不需要等待复杂的控制面收敛。
这就是 OpenAI 想消掉的一类问题:不是把故障变没,而是让故障不再打断训练。
一句人话总结:
显卡负责算,MRC 负责别让显卡互相等。
证据:这不是实验室玩具,已经进了训练集群
这篇文章真正有分量的地方,在于 OpenAI 给了生产证据。
多路径可靠连接(MRC)已经部署在 OpenAI 最大规模的英伟达 GB200 超级计算机中,包括甲骨文云基础设施(Oracle Cloud Infrastructure)在 Texas Abilene 的站点,以及微软 Fairwater 超级计算机。
OpenAI 还说,这套机制已经用于训练多个 OpenAI 模型,相关硬件来自英伟达和博通。
更关键的是故障场景。
OpenAI 观察到,在足够大的训练网络里,链路抖动不是偶发异常,而是常态。文章提到,训练中曾出现零层和一层交换机之间每分钟多次链路抖动(link flap),但多路径可靠连接(MRC)让这些情况对同步预训练任务没有可测量影响。
还有一个更硬的例子。
在一次训练 ChatGPT 和 Codex 前沿模型时,OpenAI 重启了 4 台一层交换机。按过去的经验,这种操作需要非常谨慎地和训练团队协调。使用多路径可靠连接(MRC)以后,不需要协调训练作业团队。
这句话背后的含义很重。
当基础设施足够大时,真正的先进性不是“永不出故障”,而是“故障发生时,业务不需要知道”。
行业判断:OpenAI 不只是在买算力,也在定义算力怎么被使用
很多人看大模型公司,会盯模型榜单、参数规模、上下文长度、编程能力。
这些当然重要。
但 OpenAI 这篇文章说明,头部竞争已经下沉到更难复制的地方:数据中心网络、训练控制面、故障恢复、开放标准。
更值得注意的是,多路径可靠连接(MRC)不是只藏在 OpenAI 内部。OpenAI 通过开放计算项目(OCP)发布规格,明显希望把它推成更广泛的行业基础设施标准。
这件事有两个含义。
第一,OpenAI 不是单纯采购更多图形处理器(GPU)。
它在改造“显卡如何被组织成训练系统”。未来谁能把更多显卡稳定地连成一台超级训练机器,谁才真正拥有更高质量的算力。
第二,AI 基础设施会越来越像云计算早期。
外面看是模型发布,里面拼的是网络、存储、调度、容错、标准化。普通开发者看到的是接口,基础设施团队看到的是一整套工程体系。
这也是为什么我认为,这篇文章不只是网络工程师该看。
做架构、做运维、做平台、做 AI 应用的人都该看。
因为它提醒我们:当模型能力继续扩大,真正决定上限的,往往不是某个单点能力,而是整套系统能不能稳定协同。
未来的 AI 公司,先是模型公司,最后都会变成超级基础设施公司。
你如果只想看热闹,就看下一次模型发布。
你如果想看门道,就要看这种文章:它告诉你,大模型真正的护城河,正在从模型页面一路沉到机房交换机里。
原文链接: https://openai.com/index/mrc-supercomputer-networking/
配图用途索引
- 对比传统训练网络中的单路径拥塞、尾延迟和交换机故障对同步训练的影响。
- 展示多路径可靠连接(MRC)的多平面网络、包喷洒、源路由和故障绕行机制。